





I. L'article original▲
Le site Qt Labs permet aux développeurs de Qt de présenter les projets, plus ou moins avancés, sur lesquels ils travaillent.
Nokia, Qt, Qt Quarterly et leurs logos sont des marques déposées de Nokia Corporation en Finlande et/ou dans les autres pays. Les autres marques déposées sont détenues par leurs propriétaires respectifs.
Cet article est la traduction de l'article Improving the rendering performance with more SIMD de Benjamin paru dans Qt Labs.
II. Une seule instruction pour de multiples données (SIMD)▲
L'une des méthodes pour que Qt 4.7 aille plus vite que ses prédécesseurs est d'utiliser mieux les processeurs. Les processeurs modernes ont des moyens d'exécuter une seule instruction sur plusieurs sets de données à la fois. Ceci s'appelle le single instruction, multiple data, soit SIMD. En particulier, les processeurs x86 modernes ont des extensions SSE, alors que les ARM Cortex ont Neon.
Le principe est simple. Voici un cas où on a une des opérations simples à effectuer sur de multiples données.
quint32 a[256];
quint32 b[256];
quint32 c[256];
// [...]
for (int i = 0; i < 256; ++i)
{
c[i] = a[i] + b[i];
}Sur des processeurs supportant le SIMD, ce code peut être amélioré en appliquant les instructions sur les différentes variables. Par exemple, avec SSE2, le code suivant charge quatre données, applique une opération d'addition et stocke la valeur dans une dernière variable :
quint32 a[256];
quint32 b[256];
quint32 c[256];
// [...]
for (int i = 0; i < 256; i += 4)
{
__m128i vectorA = _mm_loadu_si128((__m128i*)&a[i]);
__m128i vectorB = _mm_loadu_si128((__m128i*)&b[i]);
__m128i vectorC = _mm_add_epi32(vectorA, vectorB);
_mm_storeu_si128((__m128i*)&c[i], vectorC);
}Le code ci-dessus contient des opérations intrinsèques que le compilateur remplace par des instructions SSE2.
Cet exemple est d'ailleurs si simple que le compilateur peut l'optimiser automatiquement en lui passant les bonnes options. Mais, dans la plupart des cas réels d'utilisation, le changement n'est pas si évident, l'algorithme doit être modifié légèrement pour fonctionner vectoriellement.
Qt utilise SIMD depuis longtemps, avec MMX et 3DNOW! par exemple. Dans Qt 4.7, l'utilisation de SSE sur x86 a été étendue, de Neon sur ARM. En utilisant SIMD plus souvent, on a gagné deux à quatre fois en vitesse à certains endroits.
III. Amélioration du moteur de rendu raster▲
Dans Qt 4.7, beaucoup de primitives de rendu ont été ré-implémentées avec SSE et Neon. Ceci affecte le système de rendu raster d'une manière très positive.
Les fonctions réécrites avec SIMD sont en général deux à quatre fois plus rapides que l'implémentation générique. Des tests de performances aussi petits peuvent donner de fausses pistes ; ainsi, pour mesurer l'impact sur une utilisation réaliste, on a utilisé la suite de test de WebKit.
Pour le test de défilement, on charge les cinquante pages Web les plus visitées et on les défile de haut en bas. Pour ce test, on obtient les améliorations suivantes, en comparaison avec Qt 4.6, sans le moindre SIMD.
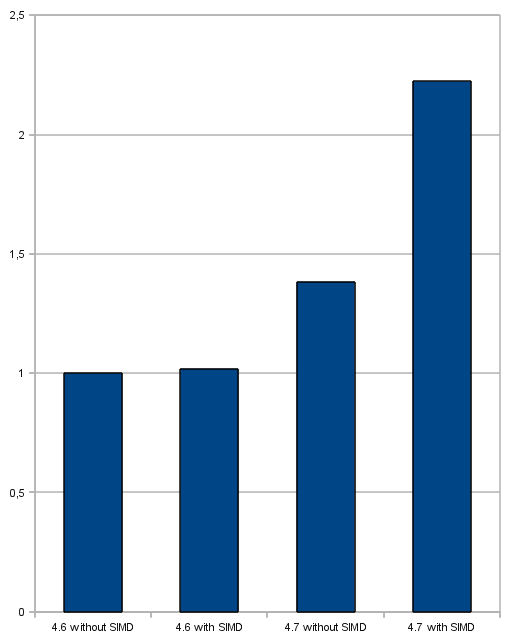
Les tests ont été lancés avec la même version de WebKit dans tous les cas, pour éviter l'influence des améliorations du moteur.
IV. Compiler avec SIMD▲
On ne doit rien faire de spécial pour profiter de ces améliorations de Qt. Lors de la compilation, le script configure détecte les fonctionnalités supportées par le compilateur. On peut voir les extensions supportées dans le résumé affiché en ligne de commande.
Supporter les extensions CPU à la compilation ne signifie pas qu'elles seront utilisées effectivement. Quand une application démarre, Qt détecte ce qui est disponible et utilise les fonctions les plus rapides disponibles pour le processeur sous-jacent.
Avec plus de SSE, le code est plus sensible à l'alignement. Malheureusement, certains compilateurs ont des bogues en ce qui concerne l'alignement des vecteurs. Avoir un compilateur récent est une bonne idée pour avoir les meilleures performances, tout en évitant certains crashs.
V. Le futur▲
Les améliorations ne sont pas encore terminées. Les fonctions les plus communes ont été optimisées, mais beaucoup de méthodes moins communes peuvent elles aussi être améliorées. Ce dernier mois (NDT : août 2010), chaque semaine, quand on pensait en avoir fini, Andreas revenait avec une nouvelle idée pour un nouveau cas d'utilisation. Ces améliorations font leur bout de chemin jusqu'à la branche Qt 4.7 et on peut déjà s'attendre à ce que Qt 4.7.1 soit un peu plus rapide que Qt 4.7.0.
VI. Remerciements▲
Merci à Louis du Verdier et Maxime Gault pour leur relecture !