





I. L'article original▲
Le site Qt Labs permet aux développeurs de Qt de présenter les projets, plus ou moins avancés, sur lesquels ils travaillent.
Nokia, Qt, Qt Quarterly et leurs logos sont des marques déposées de Nokia Corporation en Finlande et/ou dans les autres pays. Les autres marques déposées sont détenues par leurs propriétaires respectifs.
Cet article est la traduction de l'article QStrings and Unicode — optimising QString::fromUtf8 de Thiago Macieira paru dans Qt Labs.
II. Introduction▲
Mais nous nous sommes arrêtés en pleine réflexion : nous sommes en 2011, pourquoi toujours nous limiter à l'ASCII ? Si on ne fait qu'écrire des messages non traduits en anglais, on a parfois besoin de caractères hors ASCII (le signe mu µ, le signe degré °, le signe copyright © et même le signe Euro €. En particulier, ce symbole € ne fait pas partie de Latin1, on doit utiliser un autre encodage pour le représenter. Ainsi, le standard de fait en 2011 pour l'échange de texte est l'UTF-8.
D'où la question : et si l'on changeait le codec par défaut de QString de Latin1 à UTF-8 ? Clairement, cela pose un certain problème, puisque la conversion depuis l'UTF-8 est beaucoup plus complexe que pour le Latin1. On perdrait beaucoup en performances, ainsi que tout le travail en SIMD que Benjamin et moi avons fourni pour cette conversion.
III. Dans les arcanes de fromUtf8▲
Après avoir passé un certain temps à optimiser fromLatin1, j'ai décidé de regarder du côté de UTF-8. La première chose à remarquer est que le code de QString::fromUtf8 appelle le même code qui est utilisé par QTextCodec. Il y a donc quelques choses qui sont possibles uniquement avec QTextCodec et pourraient ralentir la conversion : il détecte la présence d'un BOM UTF-8, essaie de restaurer un état au début et le sauve à la fin, a une option pour remplacer les mauvaises conversions par des NUL au lieu de U+FFFD.
La première chose à tenter était de rendre le code sans état ; la méthode était simple : supprimer du code. Comme visible dans le graphe final, d'une certaine manière, cela n'a pas amélioré le code. Ainsi, j'ai décidé de réécrire ce code, en me basant sur l'expérience acquise avec fromLatin1.
En passant, il fallait aussi optimiser le code pour ASCII. S'il devient le codec par défaut pour QString, on devrait s'attendre à ce que la majorité des chaînes UTF-8 passées soient aussi des chaînes ASCII, cela devrait être le cas commun à optimiser. On voit à la fin de l'article que l'on tente de lancer la conversion fromLatin1 (les meilleurs résultats depuis l'article précédent) sur les mêmes données et qu'on essaie de comparer à quel point la conversion depuis UTF-8 est plus mauvaise que celle depuis Latin1.
IV. Du code▲
L'étape suivante, après avoir écrit le code C++ générique, était d'essayer d'optimiser à l'aide d'instructions SIMD. Ainsi, j'ai copié le code depuis fromLatin1 et ai simplement dû détecter si des octets en cours de conversion avaient le bit le plus significatif dans tous les octets. Avec SSE2, c'est assez facile, il y a une instruction qui prend le bit de poids le plus élevé de chaque octet dans le registre SSE et le sauve dans un registre CPU régulier. L'algorithme est le suivant :
- charger seize octets depuis la mémoire ;
- trouver les bits de poids les plus élevés de ces octets et vérifier si au moins un a été défini ;
- dans ce dernier cas, identifier lequel.
Identifier quel bit a été défini était facile avec l'instruction Bit Scan Forward. Le résultat de ce scan de bits est aussi le premier octet non ASCII dans les données chargées. De cette manière, on garde une boucle SSE2 pour le cas commun de l'ASCII et on introduit juste une opération de type Move Mask, Bit Scan au milieu pour détecter les caractères non ASCII.
Une autre chose que j'ai faite était, même si un octet non ASCII était détecté, de toujours sauver les seize octets convertis où le caractère non ASCII a été détecté. Cela signifie qu'on a temporairement une mauvaise conversion ; on s'assure néanmoins que la partie ASCII des octets a été sauvée en mémoire.
IV-A. En ARM▲
Ensuite, j'ai tenté la même opération avec Neon sur ARM, mais deux problèmes sont apparus : un premier, facilement soluble, est que l'architecture ARM n'a pas d'opération Bit Scan Forward, mais une Count Leading Zeroes. On résout ce problème en utilisant l'instruction qui inverse les bits d'un registre.
Le plus gros problème était que Neon n'avait pas d'instruction équivalente au Move Mask de SSE2 pour extraire les bits de poids le plus fort dans le registre chargé. Après une recherche sur le Web, j'ai trouvé un algorithme pour compenser, celui que j'ai trouvé utilisait un AND et trois additions parallèles. Les performances n'étaient cependant pas au rendez-vous... J'ai préféré une solution se basant sur l'instruction VTEST pour tester le bit de poids le plus fort et ensuite déverser le contenu du registre doubleword Neon dans deux registres ARM de 32 bits. Après ça, il s'agit de code somme toute normal pour détecter le bit de poids fort et faire la conversion en UTF-8.
VI. Conclusion▲
Voici les résultats, sous forme de graphique :
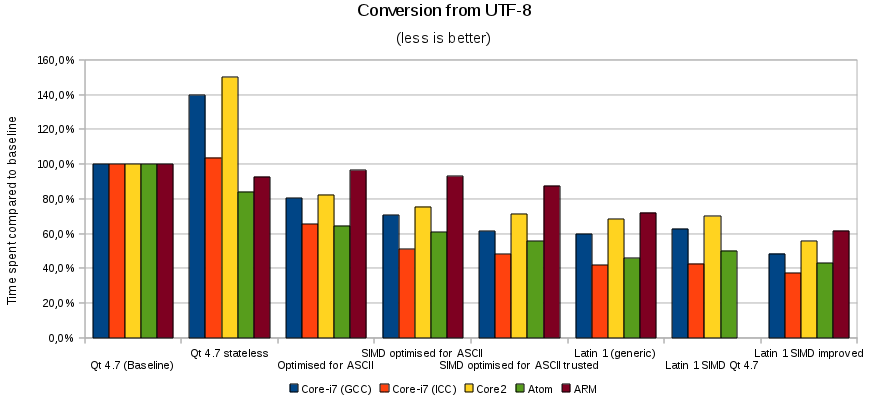
Comme la dernière fois, la première colonne sert de base et est définie à 100 %, comme le matériel testé est fort différent. La deuxième colonne compare avec le code Qt 4.7 sans les quelques portions qui effectuaient des opérations avec les états. Ainsi, comme dit précédemment, supprimer du code le rend d'une certaine manière plus lent...
La troisième colonne contient ma réécriture de la conversion UTF-8 en C++ pur, code cross-plateforme, en tentant d'optimiser pour de l'ASCII. Il n'y a pas d'amélioration flagrante pour ARM (5 %) mais, sur Atom, on monte à des opérations 50 % plus rapides que précédemment (50 % plus rapide signifiant bien que cela prend 33,3 % de temps en moins). La quatrième colonne se base sur le code SIMD en utilisant les meilleures techniques de l'article précédent, mais avec un support de l'UTF-8 ; la cinquième utilise le même code, à l'exception des tests pour des entrées UTF-8 mal formées.
Comme dit précédemment, la question à laquelle on essayait de répondre était : quel impact si l'on changeait le codec par défaut de Latin1 à UTF-8 ? Pour y répondre, les trois dernières fonctions sont les benchmarks des fonctions fromLatin1 avec les mêmes données, comparées à la même base de temps. Le meilleur code UTF-8 que j'ai réussi à écrire est entre 30 et 50 % plus lent que le meilleur code pour Latin1.
En d'autres mots, soit le réglage par défaut ne change pas, soit on garde la classe QLatin1String pour le code qui a besoin de hautes performances. L'ensemble de Qt l'utilise déjà...
VII. Remerciements▲
Merci à Louis du Verdier et à Claude Leloup pour leur relecture !