





I. L'article original▲
Le site Qt Labs permet aux développeurs de Qt de présenter les projets, plus ou moins avancés, sur lesquels ils travaillent.
Nokia, Qt, Qt Quarterly et leurs logos sont des marques déposées de Nokia Corporation en Finlande et/ou dans les autres pays. Les autres marques déposées sont détenues par leurs propriétaires respectifs.
Cet article est la traduction de l'article Improving string performance with SIMD: the revenge (fromLatin1) de Thiago Macieira paru dans Qt Labs.
II. Introduction▲
Regarder du code assembleur n'a du sens que si on peut comprendre ce qu'il s'y passe. Évidemment, il est nécessaire de comprendre l'assembleur. Par delà, on doit vraiment comprendre ce qu'il se passe. Regarder des fichiers complexes comme ceux du moteur de rendu Raster est assez inutile, puisque tout est imbriqué l'un dans l'autre, c'est un discours bafouillant. Lire le code de quelque chose de plus facile, comme QString, produit quelques résultats, comme ce que j'ai obtenu l'année dernière.
La semaine dernière, j'ai trouvé une instruction que je ne connaissais pas encore : PMOVZXBW, des extensions SSE4.1 (Parallel MOVe with Zero eXtension from Byte to Word, déplacement parallèle avec extension de zéros d'octet à mot, l'équivalent SIMD de la bonne vieille instruction MOVZX). Cette instruction charge huit valeurs de huit bits chacune, les étend à l'aide de zéros jusque seize bits et les sauve dans l'un des registres SSE de 128 bits. En fait, l'extension par zéros est exactement ce que fait QString::fromLatin1, j'ai donc essayé de jouer un peu avec elle.
III. Première tentative▲
En regardant le code de QString::fromLatin1, la version générique est la suivante :
while (len--)
*dst++ = (uchar)*src++;Il s'agit simplement d'une opération de remontée, qui est facilement parallélisable. Un premier instinct : ne charger que huit bits puis stocker dans seize bits (dans le monde x86, des quadwords et des double-quadwords). C'est le cas le plus simple possible. Mais, à la lecture des manuels des processeurs précédents, on se souvient qu'ils peuvent charger seize bits, pourvu que les conditions nécessaires soient rencontrées. De plus, en tentant l'expérience, on remarque que cela finit par être plus lent que le code actuel, qui utilise déjà SSE2 sur x86.
Le code actuel ne charge pas huit bits. À la place, il charge seize bits et utilise les instructions disponibles sur SSE2 (en opposition avec SSE4.1) pour les « décompresser ». Maintenant, les instructions pour cette décompression étaient prévues pour intercaler les valeurs de deux registres, comme indiqué dans la figure ci-dessous, du Intel 64 and IA-32 Architectures Software Developer's Manual (page 4-281).
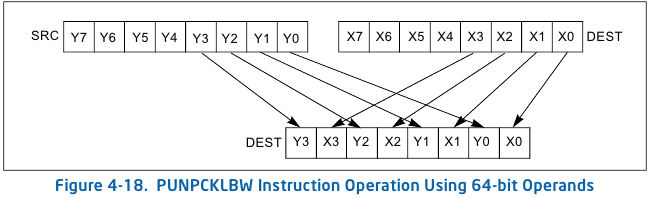
En passant, rendons à César ce qui appartient à César : le code SSE2 actuel n'est pas de moi, c'est Benjamin Poulain qui l'a écrit pour Qt 4.7.
Ainsi, j'ai tenté une seconde approche. Au lieu de charger huit bits à chaque fois, pourquoi ne pas essayer de charger seize bits comme actuellement ? J'ai essayé d'éviter les instructions de décompression, puisqu'il semble que les utiliser pour de l'extension par zéros est exagéré. Ainsi, l'idée était de charger seize bits, étendre par des zéros les huit bits les plus bas à seize bits, les stocker, déplacer les huit bits du haut dans les plus bas (à l'aide de l'extension SSE4.1 PSRLDQ, packed shift right logical double-quad) et répéter l'opération d'extension puis de stockage. Aux tests, le résultat était approximativement aussi rapide que le code utilisant la décompression. En d'autres mots : ça n'en vaut pas la peine, SSE4.1 n'est disponible que sur les processeurs Intel Core-i7, alors que SSE2 est plus répandu.
IV. Méthode empirique▲
À ce point, j'ai décidé d'utiliser une méthode empirique : utiliser les chargements alignés et les stockages. Ainsi, j'ai essayé une série de prologues d'alignement, tentant de m'assurer que j'alignais les mémoires (choisies parce que, l'année dernière, il est apparu que l'on peut s'adresser à deux mémoires par itération, mais seulement un seul chargement). Mais, comme précédemment, l'alignement prenait trop de temps pour que cela en vaille la peine. Puisque la majorité des chaînes à convertir sont assez petites (en moyenne, 17,82 caractères), la complexité de ces prologues dépasse les bénéfices engrangés par l'alignement des mémoires. Et on doit toujours faire des chargements non alignés. Pour que cela ait réellement un impact, les chaînes doivent être plus grandes que seize octets, soit huit caractères, en plus de la longueur du prologue (soit, dans le cas de QString, sept caractères dans 95 % des cas, trois dans les autres).
Un résultat intéressant est cependant apparu. Aligner le prologue (les données avant les opérations SIMD) n'a pas donné de gain perceptible, mais dérouler l'épilogue que du contraire. Le code qu'on a actuellement dans Qt 4.7 ne fait qu'abandonner la boucle générique (voir la ligne 3782). Cependant, on savait que la fin de l'opération fait au plus quinze caractères, on l'a donc déroulée manuellement dans une très longue fonction. Cela, en plus d'autres choses simples pour demander au compilateur de faire moins à chaque boucle, a eu l'effet escompté.
V. Le côté ARM de la vie▲
Finalement, on a décidé de regarder du côté de ARM. Quand Benjamin a fait ce travail pour Qt 4.7, il a conclu que les améliorations sur ARM ne valaient pas l'effort fourni. En y regardant de plus près, on a réussi à améliorer les performances de 25 %, un peu plus en écrivant le code assembleur à la main.
Le set d'instructions de ARM Neon contient des combinaisons très intéressantes d'instructions pour les chargements et les mémoires avec intercalage, principalement prévues pour le traitement des images. Dans ce cas-ci, on veut charger des données non intercalées, on est donc limité à des chargements de huit à seize bits (dans le monde ARM, doubleword et quadword). Le premier code que j'ai écrit utilise des chargements de huit octets, un move long unsigned (soit une extension par des zéros de huit à seize bits) et une mémoire de seize octets. Puisque cela a eu un impact positif sur x86, j'ai essayé de charger seize octets, deux VMOVL.U8 et deux mémoires. Cependant, sur le processeur Cortex-A8 que j'avais pour mes tests, cela n'a rien amélioré, bien au contraire.
Finalement, notons que les instructions Neon pour le chargement et la mise en mémoire mettent à jour le registre d'adresse en ajoutant le nombre d'octets transférés (nous évitant la tâche de le faire nous-mêmes). J'ai donc écrit le code assembleur pour cela à la main pour voir s'il y avait un impact. Il ne fut que de 3 %.
VI. Conclusion▲
Cet article ne serait pas complet sans un graphe montrant les chiffres que j'ai obtenus :
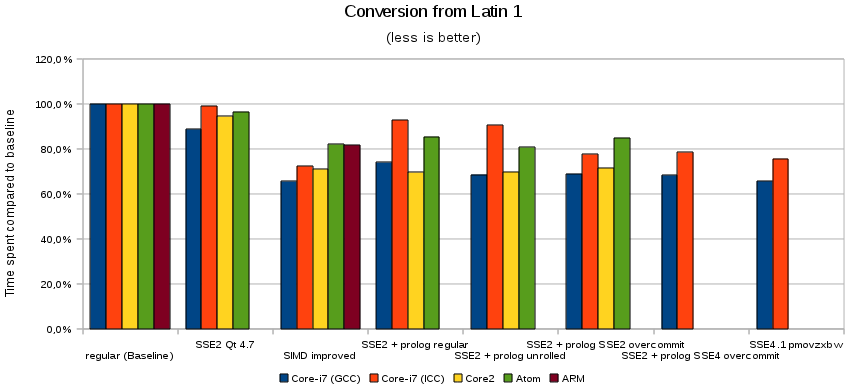
Tous les tests ont été lancés en 32 bits, même si tous les processeurs x86 que j'ai eus sous la main pouvaient lancer du code 64 bits, même l'Atom. Puisqu'il s'agit de systèmes très différents, cela n'a pas de sens de comparer l'un à l'autre ; ainsi, le premier groupe de barres est la base, soit 100 % pour tous. Le seul groupe de barres présentes dans tous les CPU est SIMD improved, ce que j'aimerais introduire dans Qt 4.8.
La colonne SSE2 Qt 4.7 est ce qu'on obtient en compilant Qt pour des systèmes équipés de SSE2. Il ne s'agit pas d'une décision prise à l'exécution, elle se fait à la compilation. La plupart des distributions Linux ne les ont pas activées.
Évitez de faire de fausses conclusions en comparant les résultats de ICC avec GCC. GCC optimise mieux, mais il est incorrect de dire que c'est mieux. Il appert simplement que la base pour GCC est plus haute. Les mesures relatives sont assez stables, pas les absolues, il est donc difficile de tout comparer.
Le code source complet est disponible, évidemment ; regardez les fonctions fromLatin1_* et le test fromLatin1Alternatives.
VII. Remerciements▲
Merci à Louis du Verdier et à Claude Leloup pour leur relecture !